 n8n in a Nutshell
n8n in a Nutshell
What is Tweet Sentiment Analysis?
Tweet Sentiment refers to the underlying emotion or opinion expressed in a tweet. It can be positive, negative, or neutral, helping businesses and individuals understand public feelings and reactions about a topic, brand, or product on X (formerly Twitter).
By analyzing tweet sentiment, you can gain valuable insights into customer satisfaction, brand reputation, and trending opinions — all automatically and in real-time using tools like n8n combined with AI-powered sentiment models.
Effortless Tweet Sentiment Analysis with
n8n & GPT API

How We Built This Automation
- Method:
POST - URL:
https://api.apify.com/v2/acts/kaitoeasyapi~twitter-x-data-tweet-scraper-pay-per-result-cheapest/runs?token=YOUR_APIFY_TOKEN - Authentication: Predefined Credential (Apify API)
- Headers:
[ { "Content-Type": "application/json" } ] - Body (JSON):
{ "from": "realDonaldTrump", "twitterContent": "war OR conflict OR Iran OR Israel OR military OR missile OR attack OR sanctions OR diplomacy OR peace OR nuclear OR troop OR battlefield OR strike OR invasion OR ceasefire OR missilestrike OR defense OR escalation", "maxItems": 500, "queryType": "Top", "lang": "en" }
💡 Tip:
- You can customize
twitterContentto match your niche. Example: “AI OR ChatGPT OR LLM OR machine learning” for AI trends, or “Olympics OR gold medal OR Paris 2024” for sports updates. - You can also change the
fromfield to scrape tweets from any person you want (e.g., kanyewest). - You can change the
queryTypeto any supported type, such as latest, top, or mixed depending on your needs.

datasetId after the actor runs. We captured this ID using an n8n Set or Function node for use in the next step.

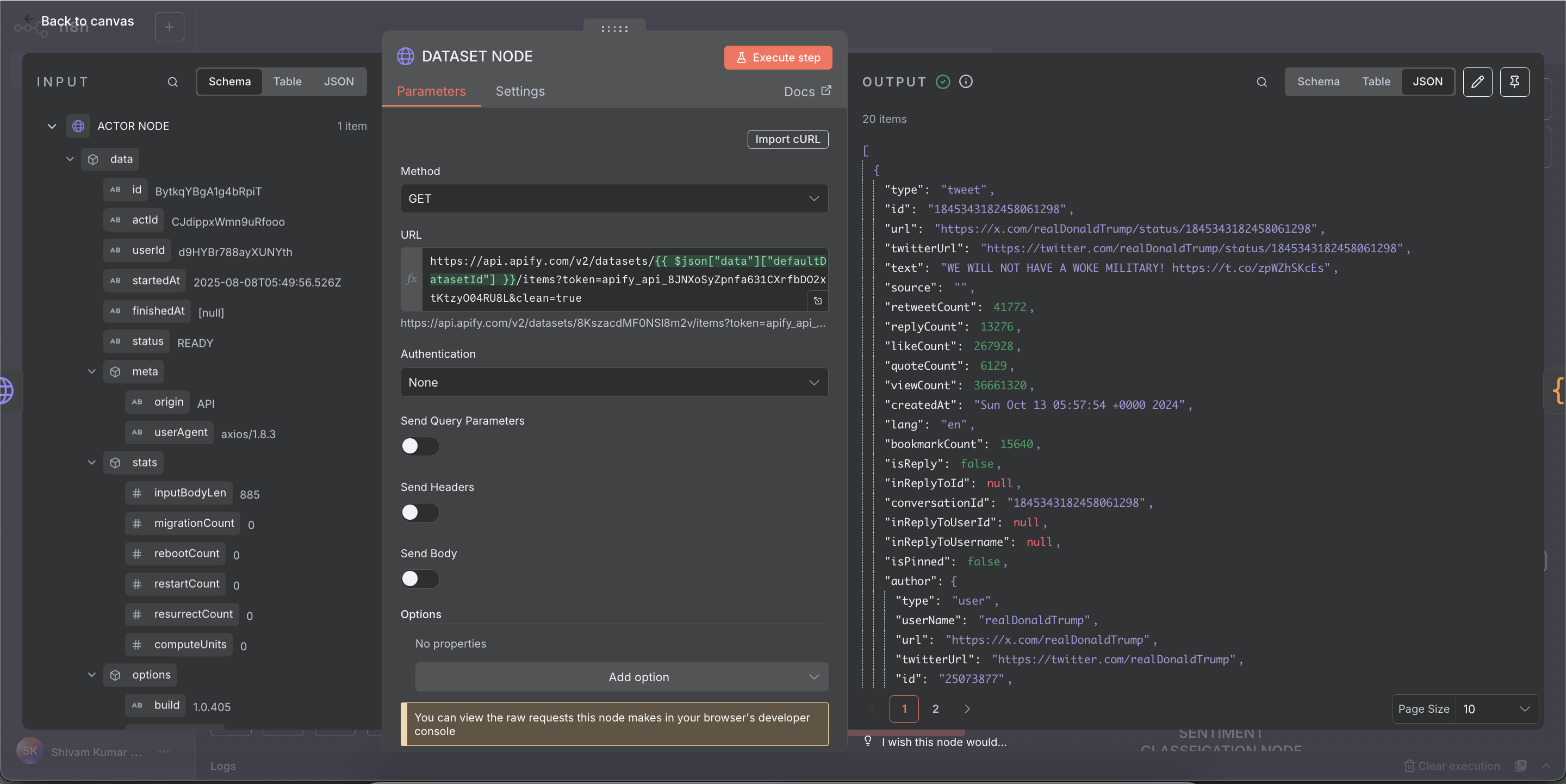
- Method:
GET - URL:
https://api.apify.com/v2/datasets/{{ $json["data"]["defaultDatasetId"] }}/items?token=YOUR_API_TOKEN&clean=true - Authentication: None (API token included in URL)
- Headers: None
- Body: None
const items = $input.all();
const transformedItems = items.map(item => {
const { id: originalId, ...rest } = item.json;
const numericId = Number(originalId);
const newId = numericId === -1 ? Math.floor(Math.random() * 1000000000) : numericId;
return { id: newId, ...rest };
});
return transformedItems;
Sometimes, if the actor doesn’t find real tweets (due to errors or no matches), it sends a mock tweet with id = -1. This code handles that by replacing -1 with a random unique ID.

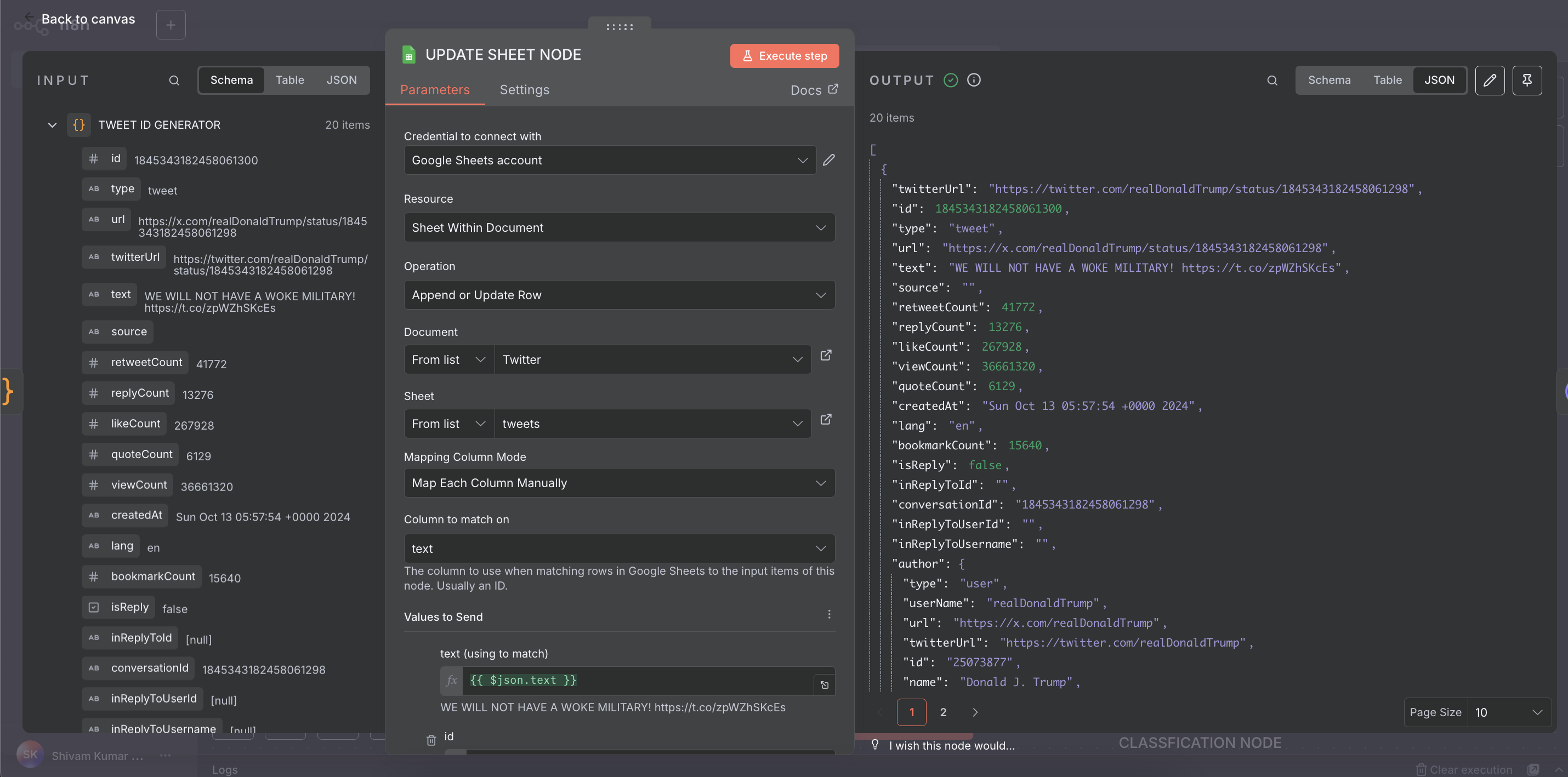
- Credential: Connected Google Sheet account
- Resource: Sheet Within Document
- Operation: Append or Update Row
- Document:
Twitter - Sheet:
tweets - Mapping: Mapped each tweet field manually to columns
cardiffnlp/twitter-roberta-base-sentiment model via an HTTP Request node.
HTTP Request Configuration:
- Method:
POST - URL:
https://api-inference.huggingface.co/models/cardiffnlp/twitter-roberta-base-sentiment - Headers:
[ { "Authorization": "Bearer YOUR_HF_API_KEY" }, { "Content-Type": "application/json" } ] - Body (JSON):
{ "inputs": "{{ $json.text }}" }
💡 Tip:
You can try changing the model to another one, like distilbert-base-uncased-finetuned-sst-2-english, for faster results while maintaining good accuracy. Feel free to explore other Hugging Face models to find the best fit for your needs!
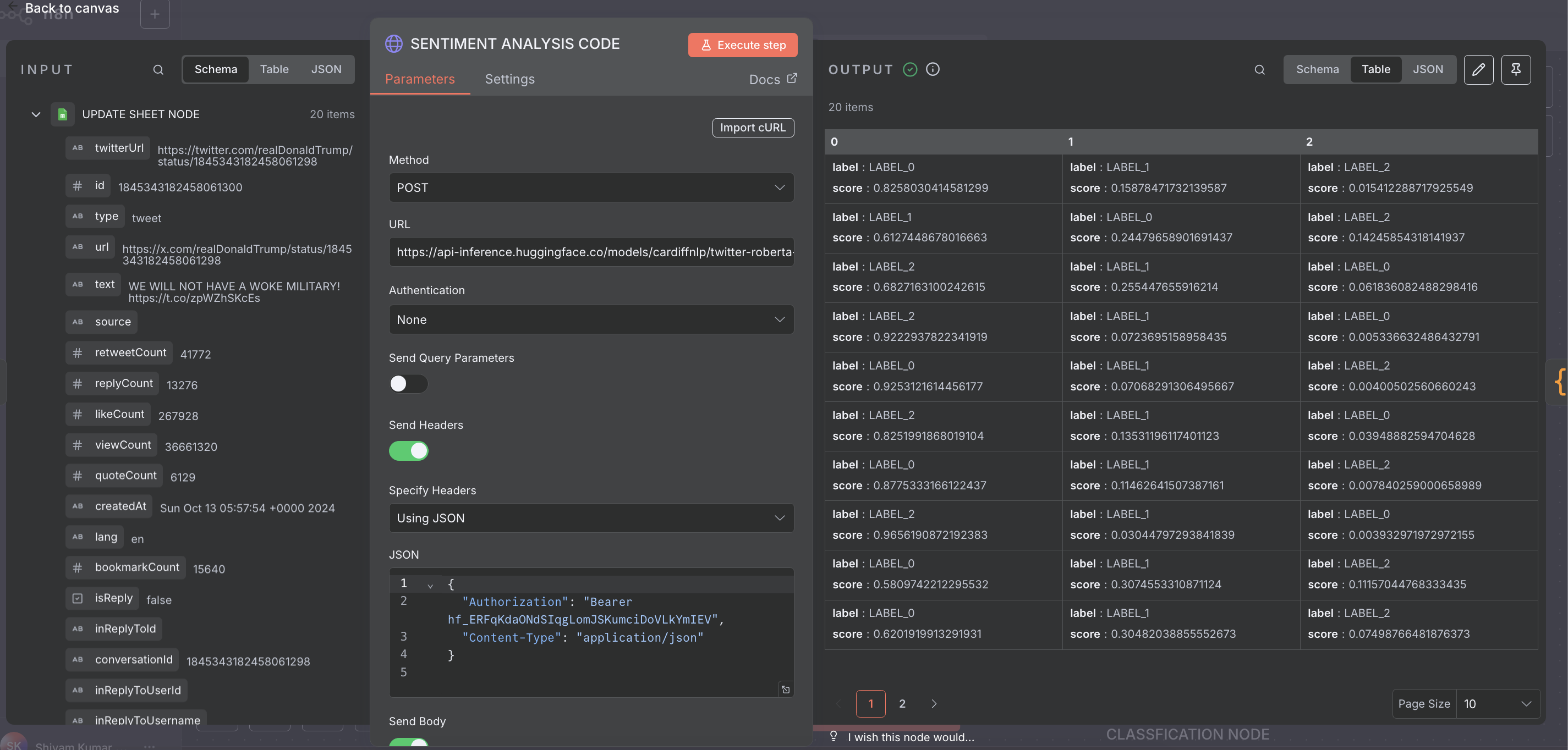
LABEL_0, LABEL_1, and LABEL_2, which correspond to negative, neutral, and positive sentiments respectively.
To convert these into more understandable terms, we used an n8n Code node with the following JavaScript code:
// Process all input items
const items = $input.all().map(item => {
// Create a copy of the original JSON data
const newItem = {...item.json};
// Calculate sentiment if not already present
if (!newItem.sentiment) {
const labelMap = {
"LABEL_0": "negative",
"LABEL_1": "neutral",
"LABEL_2": "positive"
};
// Get all available results
const results = [];
['0', '1', '2'].forEach(key => {
if (newItem[key]) {
results.push(newItem[key]);
}
});
// Determine sentiment if we have results
if (results.length > 0) {
const top = results.reduce((max, current) =>
(current.score > max.score) ? current : max,
{score: -Infinity}
);
newItem.sentiment = labelMap[top.label] || 'unknown';
} else {
newItem.sentiment = 'unknown';
}
}
return {json: newItem};
});
return items;
This Code node reads each item’s label, maps it to a clear sentiment category, and adds a new sentiment field with the result.

sentiment value back to the same Google Sheet, giving us a final dataset with both tweet data and analyzed sentiment.
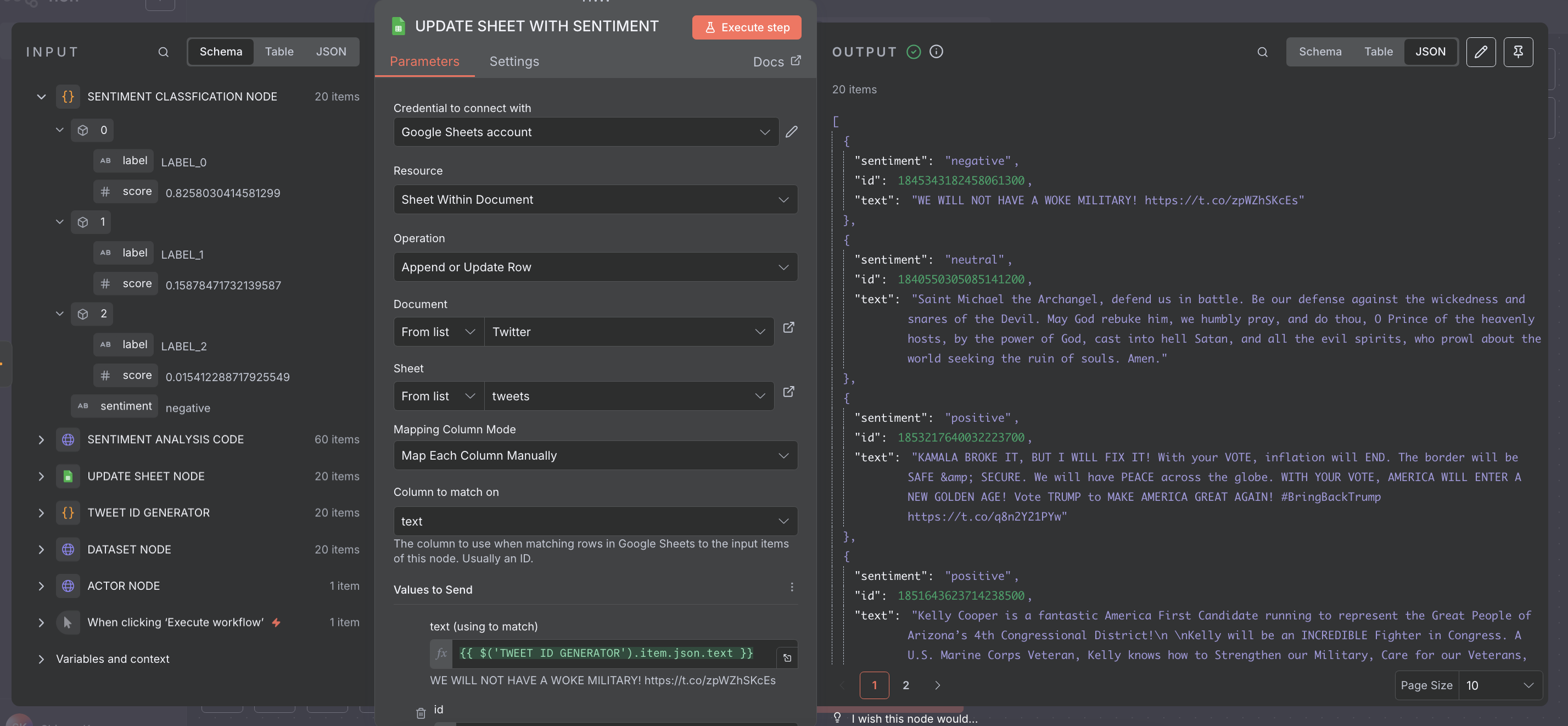
Here Is the Sheets Output Result
The scraped tweets along with their analyzed sentiments are neatly organized in Google Sheets, ready for review or further analysis.

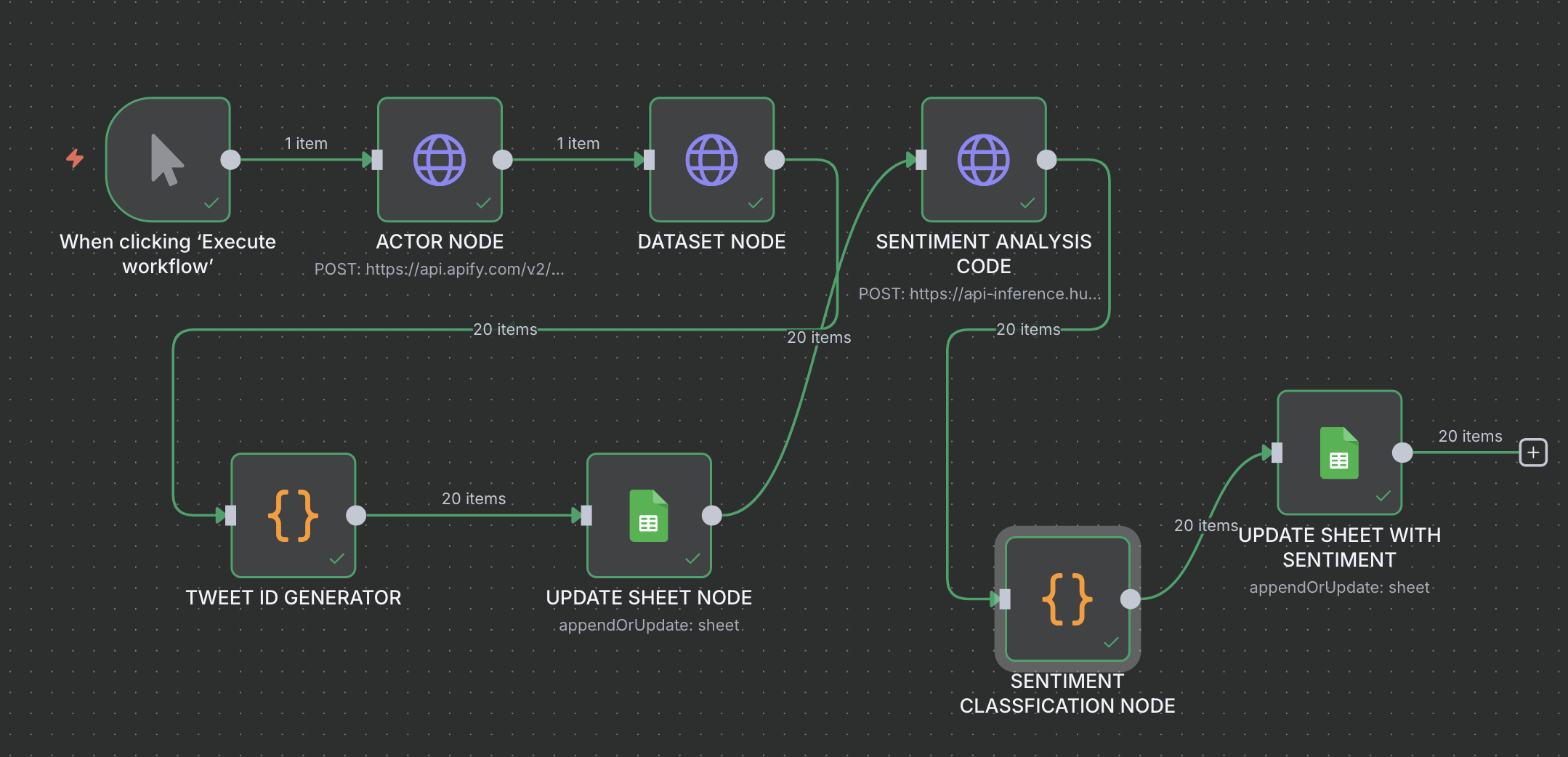
Complete Workflow of n8n Automation
Below is the full visual diagram of our n8n workflow demonstrating how all steps are connected seamlessly.