

Sections
- Introduction
- Create a scrapy Project.
- Exploring the webpages [for detail page]
- Coding Part-I [Request to detail page]
- Analyzing the listing page & coding for next page [pagination]
- Analyzing the detail page & coding to extract the information.
- Running the code
- Conclusion
- Common errors
1. Introduction
Hey internet, Welcome to this blog. Today we’ll go deep into the world of web scraping, concentrating on one of the most popular and broad databases available: IMDB, or the Internet Movie Database. For those who are unfamiliar, IMDB is a massive internet database that contains information on movies, TV shows, video games, and much more. If you haven’t already, I recommend taking a quick tour of their website.
Before we start scraping data from IMDB, it’s good to learn a bit about a tool called Scrapy. Scrapy helps us collect data from websites easily. It’s a tool made for Python, a programming language. You can learn how to use Scrapy by checking out tutorials or documentation. You can find a useful tutorial here on Scrapy’s official website to get started. This guide will teach you the basics of using Scrapy to collect data from websites.
Now with some knowledge of Scrapy, you’ll find it easier to follow along as we explore how to gather information from IMDB about movies and TV shows. So, let’s dive in!
At the end of this article, you will be able to fetch your required information about movies and TV shows. The “required information” may include Title, Released date, Cast, Director, Ratings, Genre, writers, images, videos, and many more. So for doing that, firstly, we will go to the desired listing page, analyze the webpage. Then go to the detail page and do the same. So without further ado, let’s get started.
Please note: It’s common to encounter errors during the scraping process. Don’t hesitate to leave comments or ask questions if you come across any issues. There is a section named common errors at the end of the blog, you can also refer to that. To facilitate your learning, we’ve created a GitHub repository that contains all the code snippets and resources used in this project. You can find the GitHub repository here.
2. How to Create a Scrapy Project.
Lets create a scrapy project.
- Open your terminal and write the following command.
scrapy startproject imdbscraperLet me breakdown the command for you. What we are doing? We are calling scrapy framework in the first word “scrapy”. Then we are giving second argument as “startproject” which basically creates a template scrapy project. Then at last name of the project. You can set the name as you want.
You will see the new folder made. you can simply hit ‘ls’ in linux and ‘dir’ in windows to see the contents of the directory.

- Now hit the following command to enter into the folder.
cd imdbscraper- Now open the folder in your code editor. I am using VS code for this.
Create an spider in the spider folder. You can do that by the following command.
scrapy genspider moviescraper https://www.imdb.com/search/title/?genres\=Action\&explore\=title_type%2CgenresHere, the command simply creates a spider named moviescraper that scrapes the following url after that. In layman’s term, a file named moviescraper is created which we will be working with.
Your file will look like this.
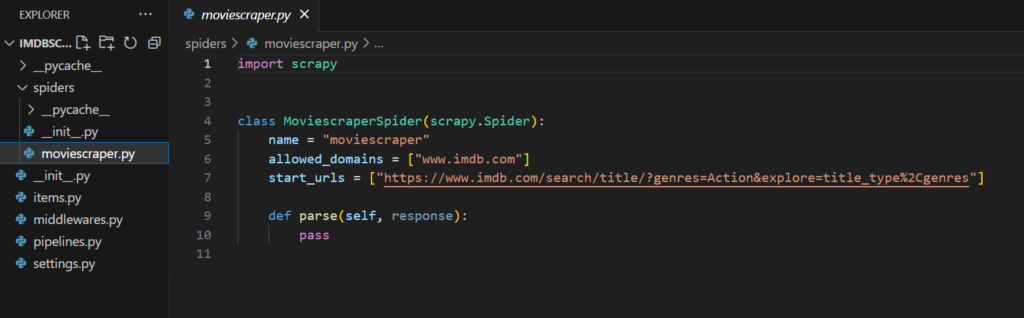
Now you can also edit the variable named “start_urls” and place the listing url inside it. Please Remove the line allowed_domains for this scraping.
It will sent the request to the link and get the response and send it to parse function as a parameter. Response contains all the html of the page.
3. Exploring the webpages [for detail page].
Now that we have created the template for coding. lets analyze the the html of the pages.
– Analyzing the listing page.
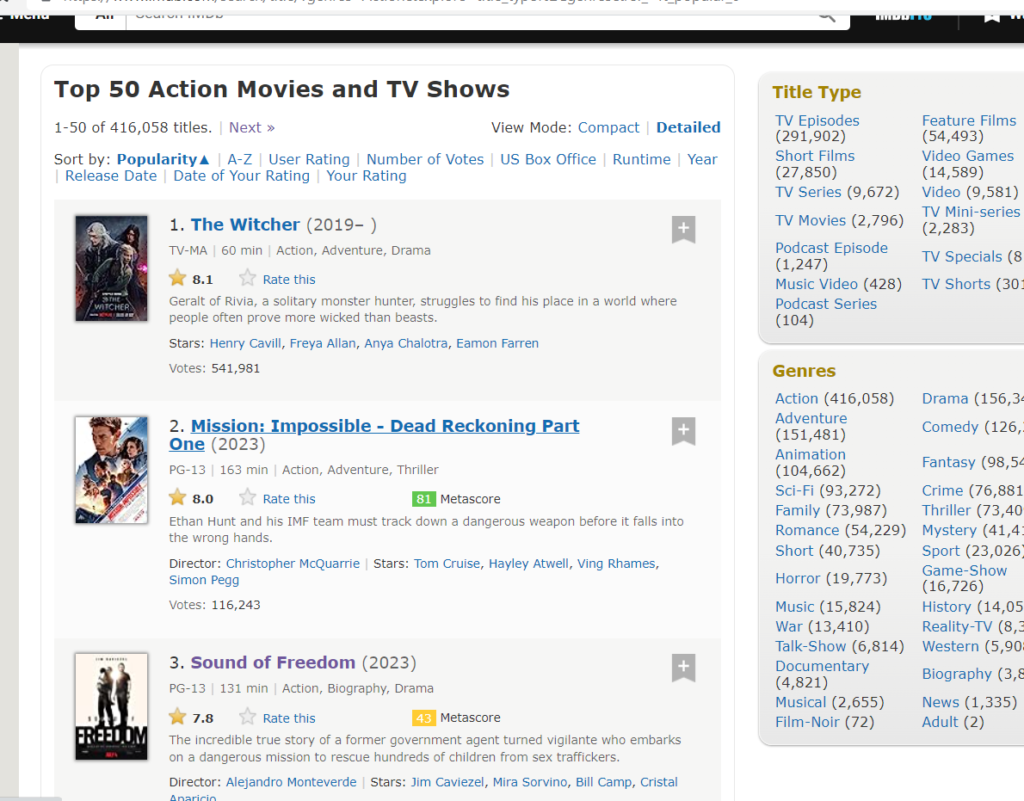
Listing page here refers to the page that contains links to various media (movies , TV shows , games). In this article I am using action genre as the listing page. I am trying to scrape all the movies and tv shows from this page. You can select your page based on your need.
Now, lets analyze the html of the page.
Firstly, Right click on the empty area of the webpage.
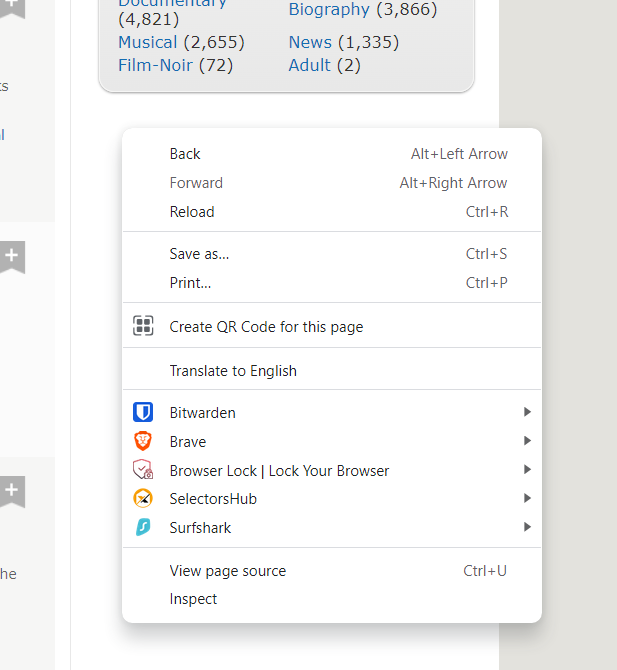
You will see many options. We are going to use two options from this. First, View page source and next inspect.
View page source – Loads all the html in a new tab provided by the servers of the website.
Inspect – Shows the html but in an interactive way. You will see why it is “interactive” later in this blog.
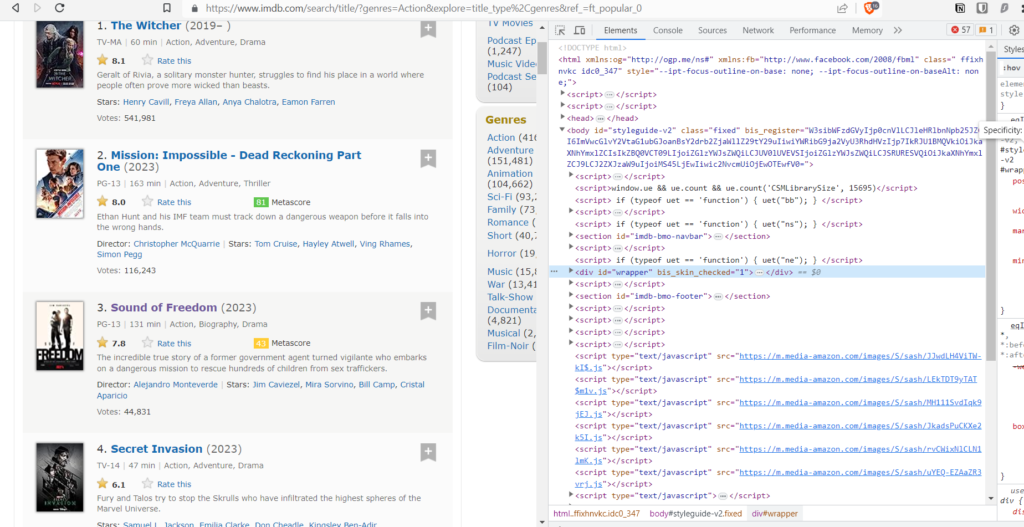
Now lets get the links of the detail page. [Detail page here refers to the specific page for the media.]
Now go to the inspect. click on this icon on the top corner of the inspect tab.
Now place your mouse to the title of the media.
Now click on it and see your inspect tab.
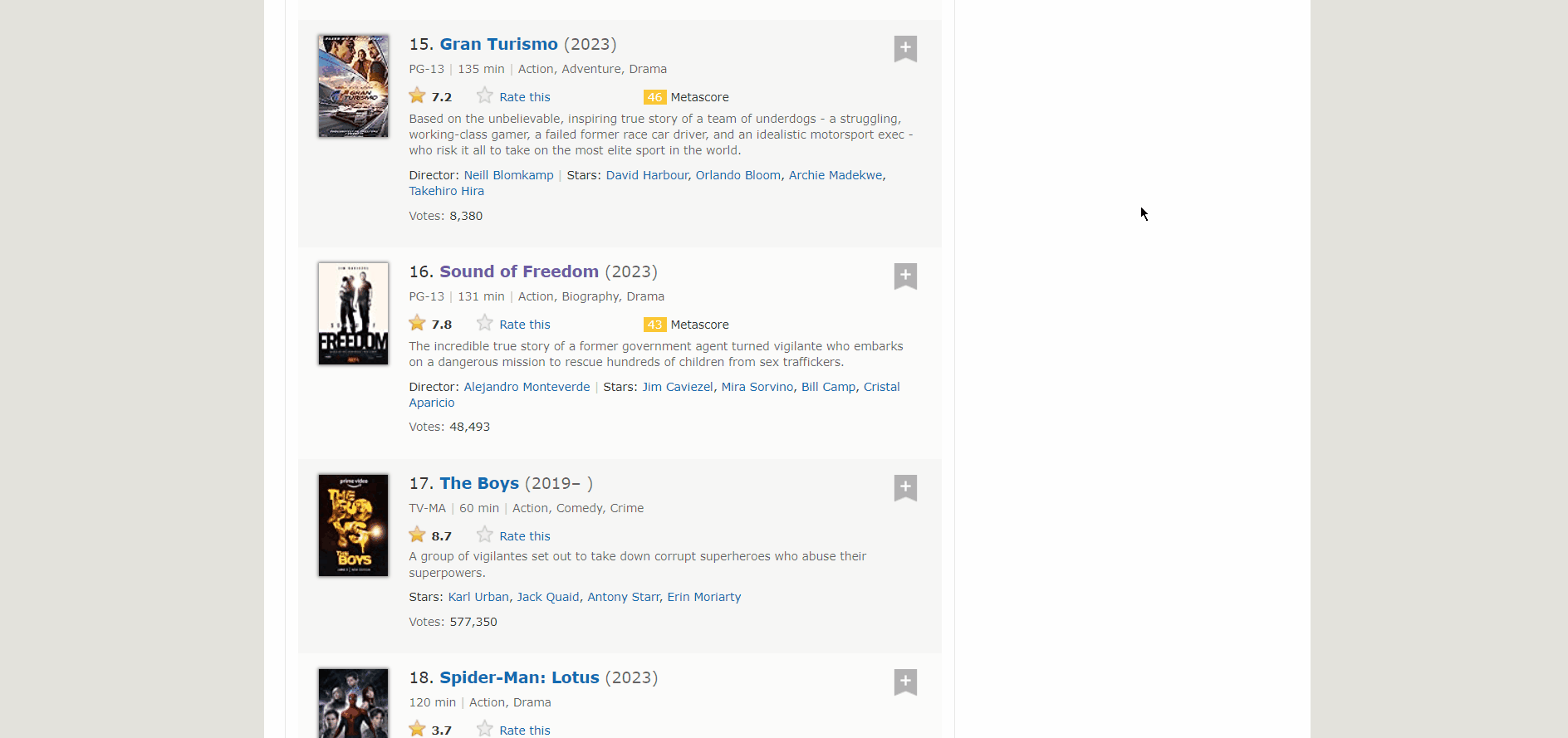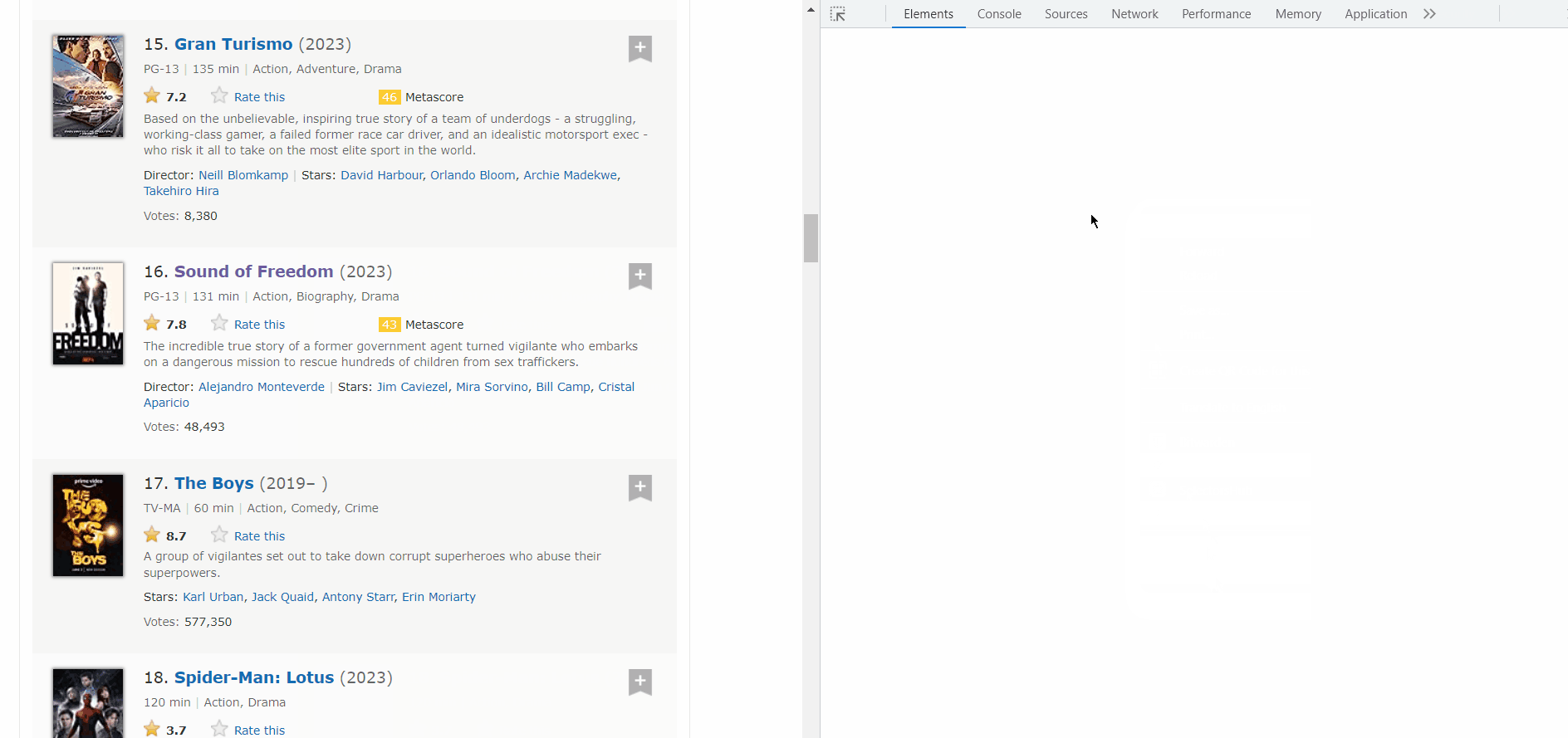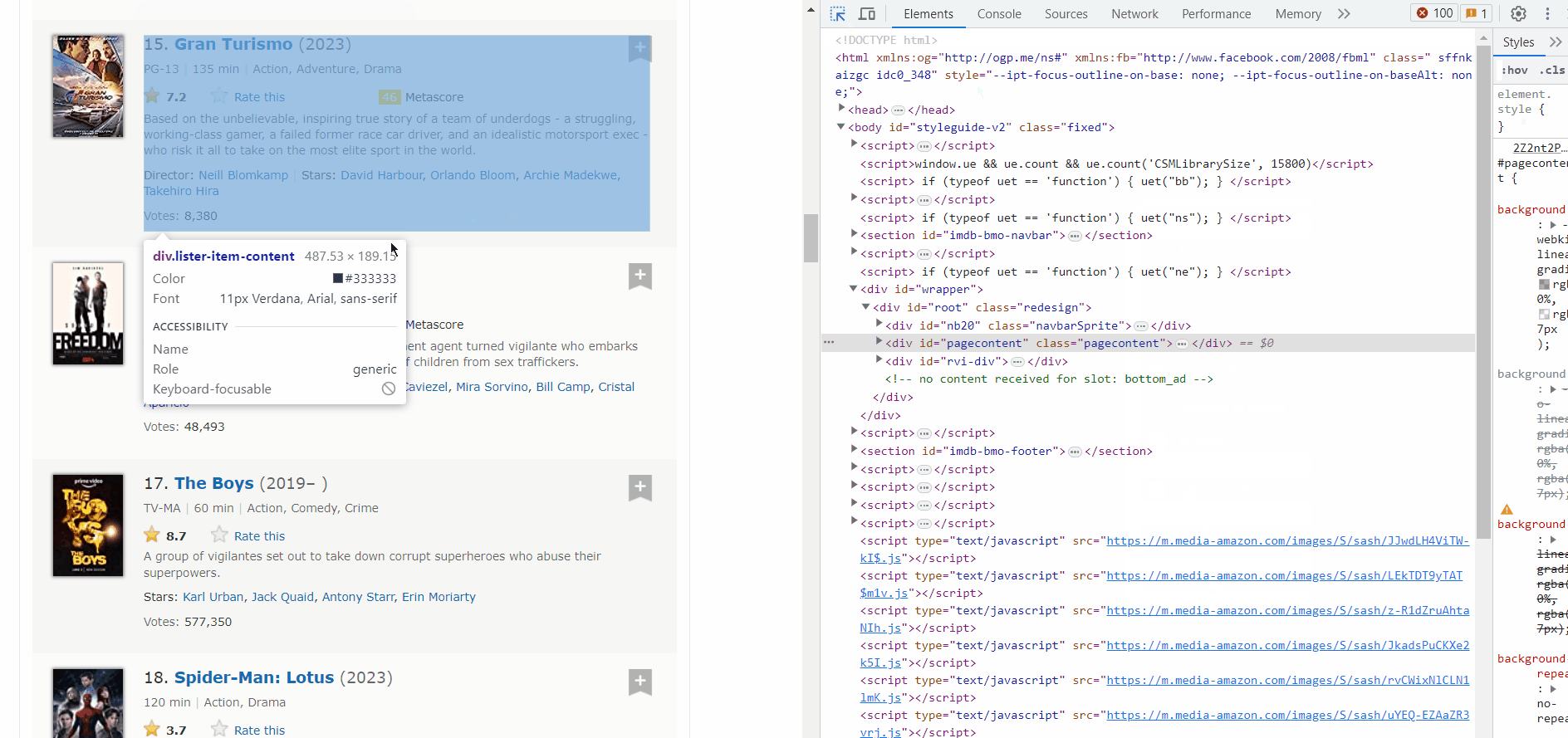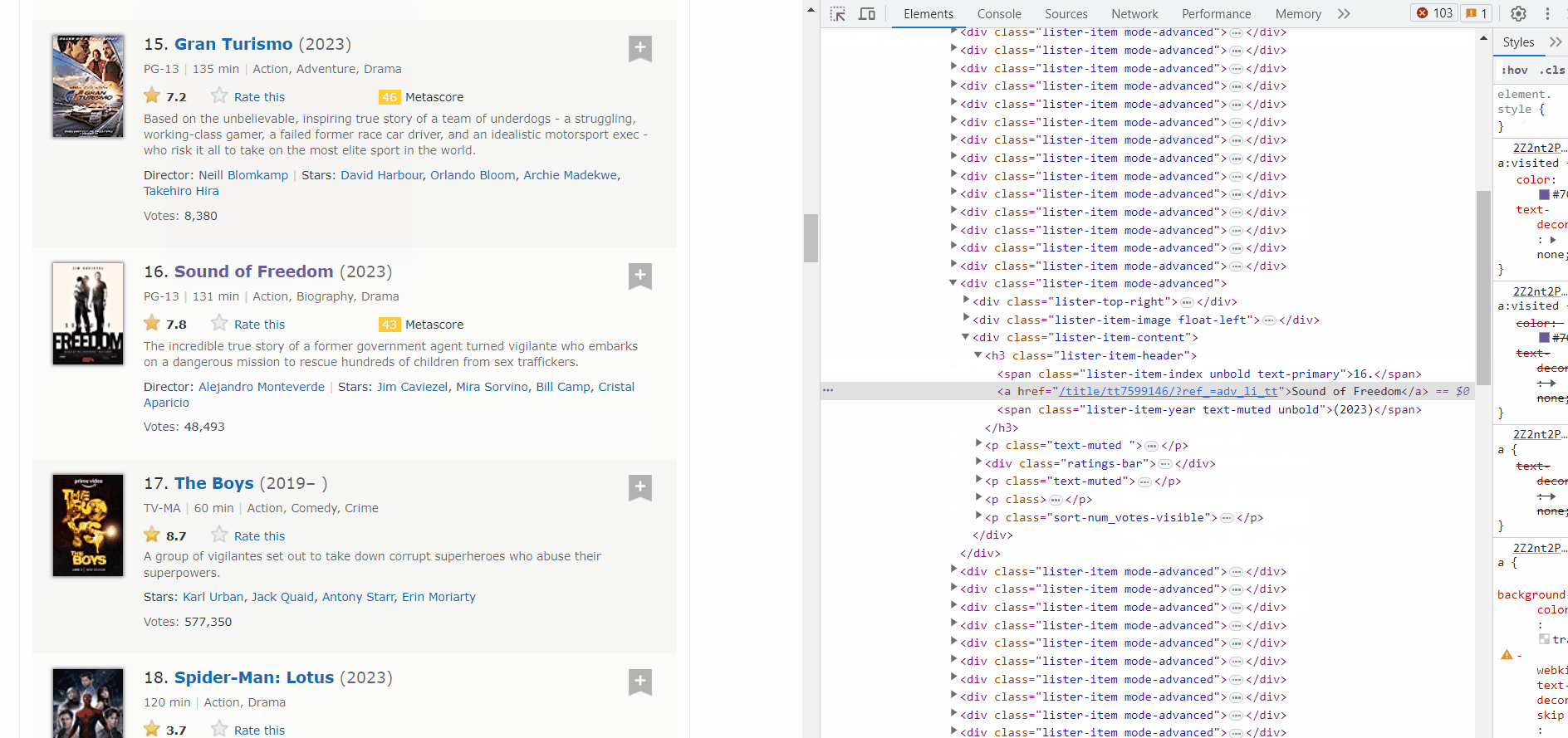
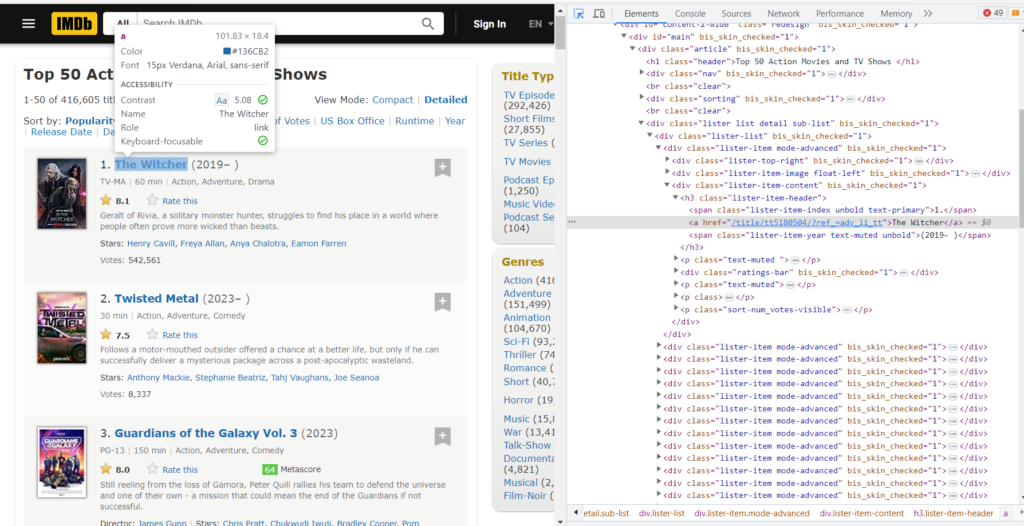
Did you see the highlighted section? That’s the exact html element of the title and the href is the link where we will be sent to when we click that title. That’s what I meant by “interactive”. Similarly, we need to get all the links for all the Media.
Now, lets get to coding and see how we can fetch all the links.
From analyzing the listing page we can assume the following things.
- All the links are inside ‘a’ tag which is inside ‘h3’ tag having class name “lister-item-header” which is inside ‘div’ tag having class name as ‘lister-item-content’.
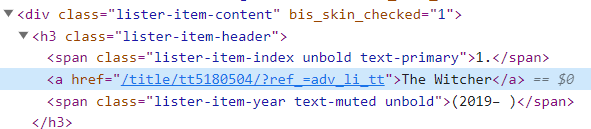
You can confirm the above assumption by inspecting other titles too.
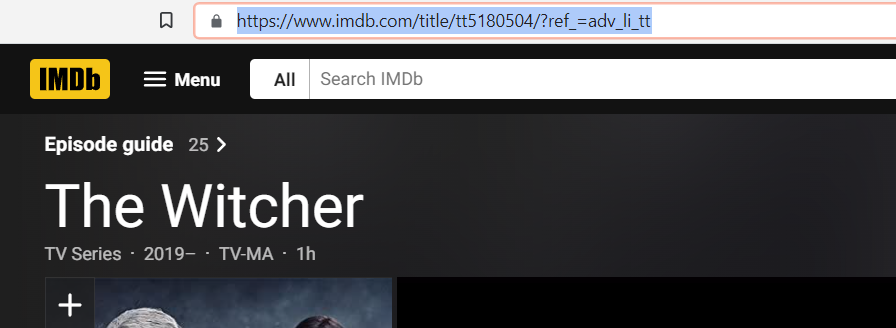
- The actual link of the detail page of the media is “https://imdb.com<href of the media>“. You can confirm this by visiting to the detail page.
4. Coding Part-I [Request to detail page]
In this section, our objective is to send requests to the detail page of the movie. In other words, we need URL of the movies. For doing that we are using parse function.
links = response.xpath('//div[@class = "lister-item-content"]/h3[@class = "lister-item-header"]//a/@href').getall()The code says. select all div from the html having class name “lister-item-content”, then go inside it to find h3 with class name ‘lister-item-header’, then finally select ‘a’ tag inside it and grab its href. The getall() function basically turns the selector into list. So basically we get all the href and it is stored in links list.
XPath is a crucial skill when working with Scrapy. It helps you navigate through the HTML structure of a web page to pinpoint and extract exactly the data you need. Understanding XPath can significantly ease your web scraping tasks, making your Scrapy projects more effective and straightforward. If you’re keen on mastering XPath for your Scrapy projects, there are resources available to aid your learning journey. For instance, the official Scrapy documentation provides a solid grounding in using XPath with Scrapy: Scrapy and XPath Documentation. Additionally, tutorials on platforms like Coursera or Udemy often cover XPath within the context of web scraping with Scrapy, which you might find beneficial. With a good grasp of XPath, your ability to efficiently harvest data with Scrapy will greatly improve, making your web scraping projects much more productive.
for link in links:
yield scrapy.Request(
url= 'https://imdb.com' + link,
callback=self.parse_details
)Now we are sending request to the detail page and the response of url will be sent to parse_detail function. That’s why its called callback.
for reference the code will look like this:
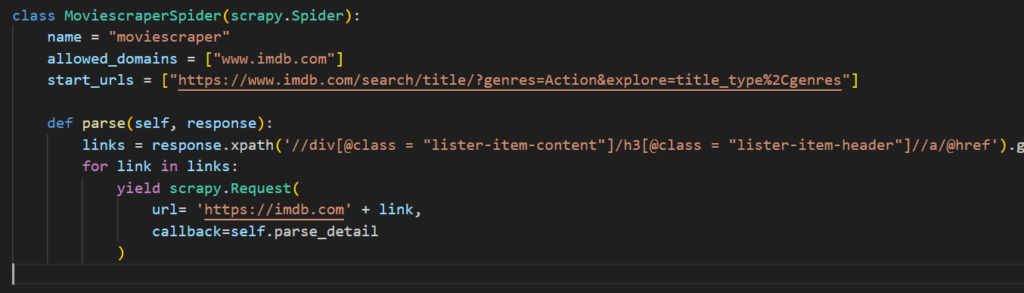
Now that you are sending response to parse_detail function. we also need to find a way to go to next page and do the same. In the next section, we will do that.
5. Analyzing the listing page & coding for next page [pagination].
Lets see how we can get the next page links.
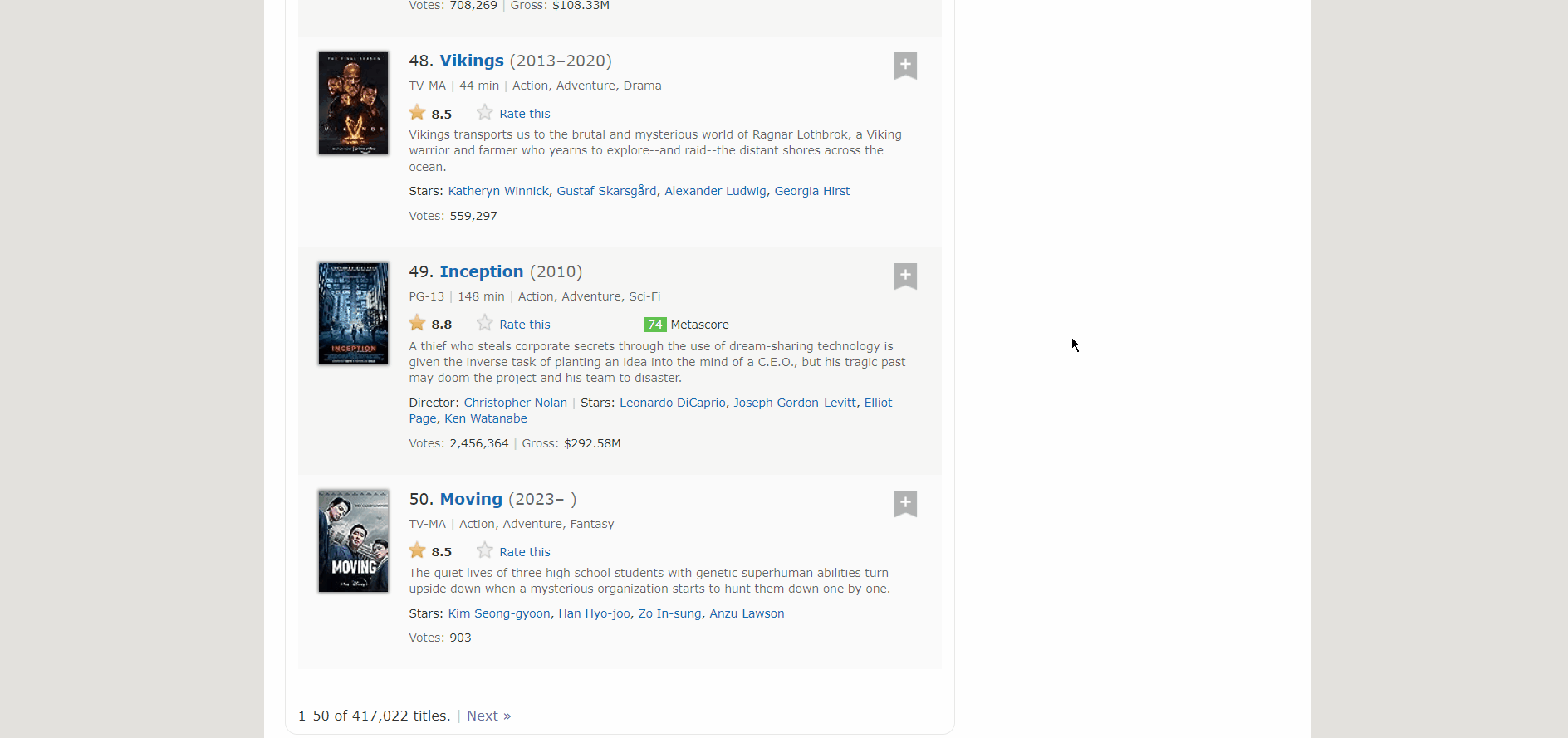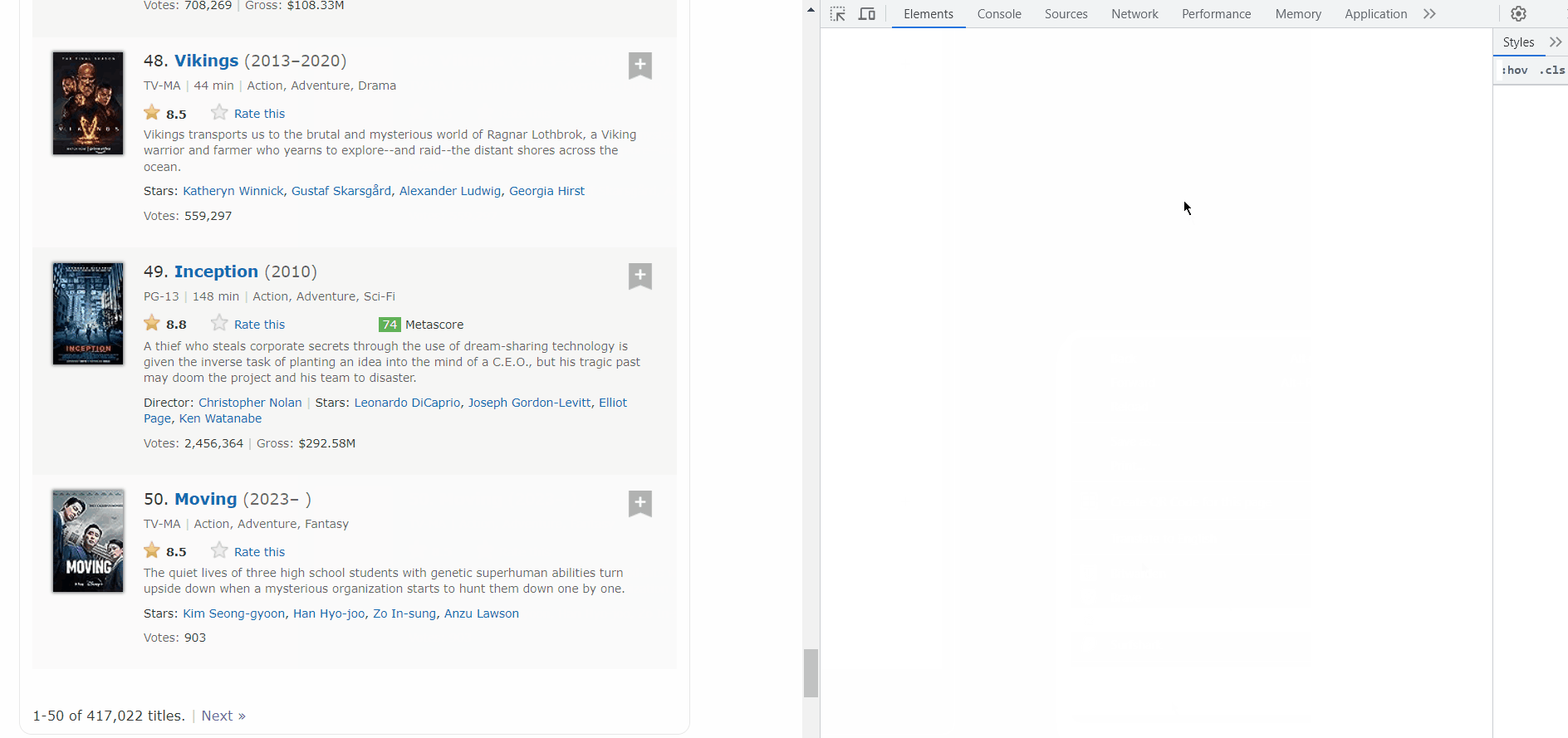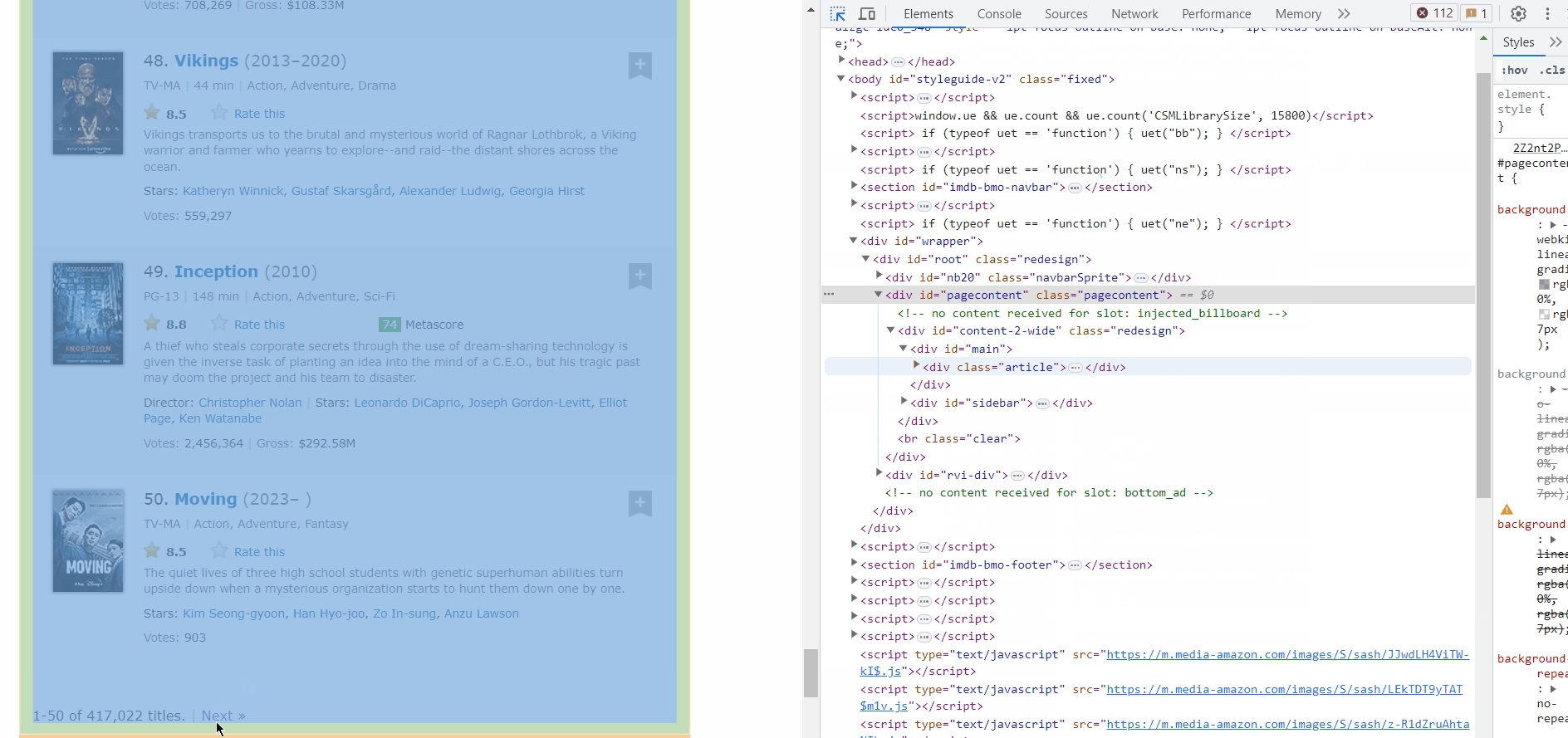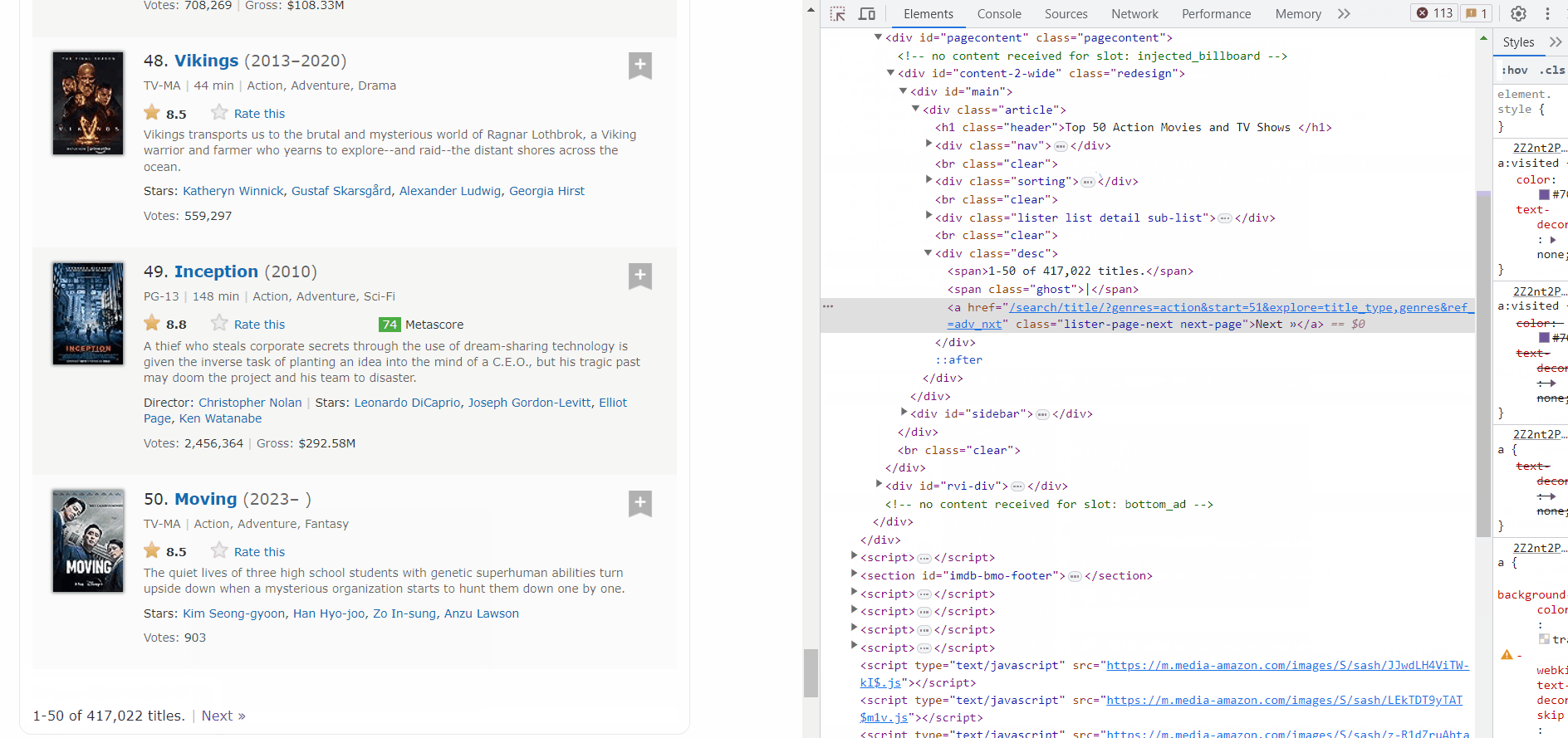
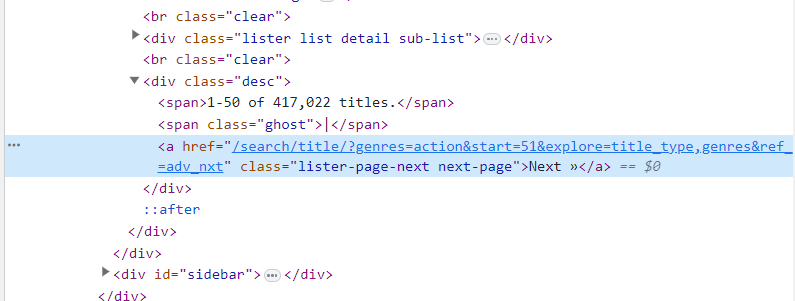
As you can see the next button is inside a ‘a’ tag with class name “lister-page-next next-page”. So we can select it using xpath. lets get to coding it.
next_btn = response.xpath('//a[@class = "lister-page-next next-page"]/@href').get()
if next_btn:
yield scrapy.Request(
url = 'https://imdb.com' + next_btn,
callback= self.parse
)Here we are selecting the ‘a’ tag with class name “lister-page-next next-page” and getting its href. Now that we have link to next page.
Create a condition which checks if next button exists or not and if it does, send the response to parse function to extract its detail pages and repeat the steps (check if it has next button or not …).
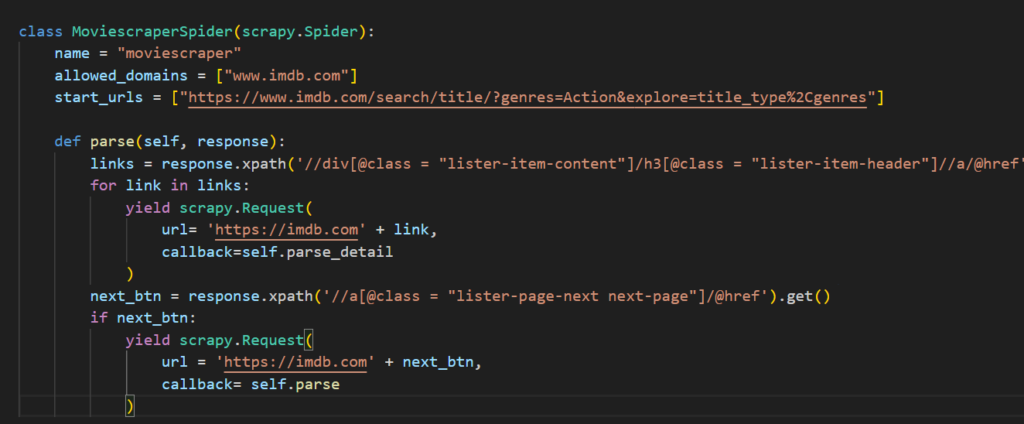
For reference, Code looks like this:
6. Analyzing Detail Page and Coding to Scrape Information.
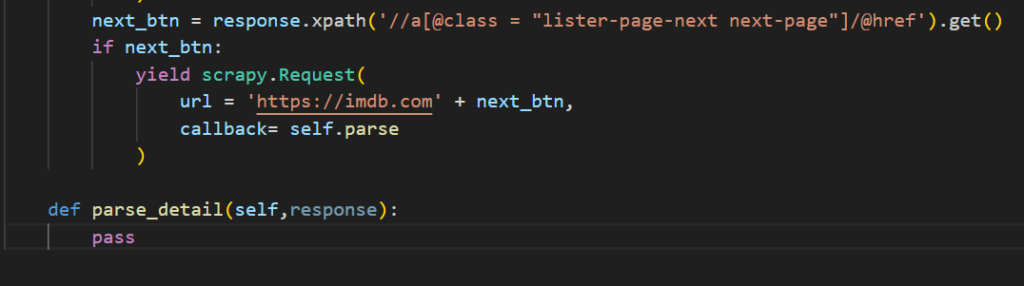
Now that we have worked on listing page. Lets see how to fetch data. Firstly, create a function named ‘parse_details’ which takes parameter as response.
We will analyze the detail page and code to it simultaneously.
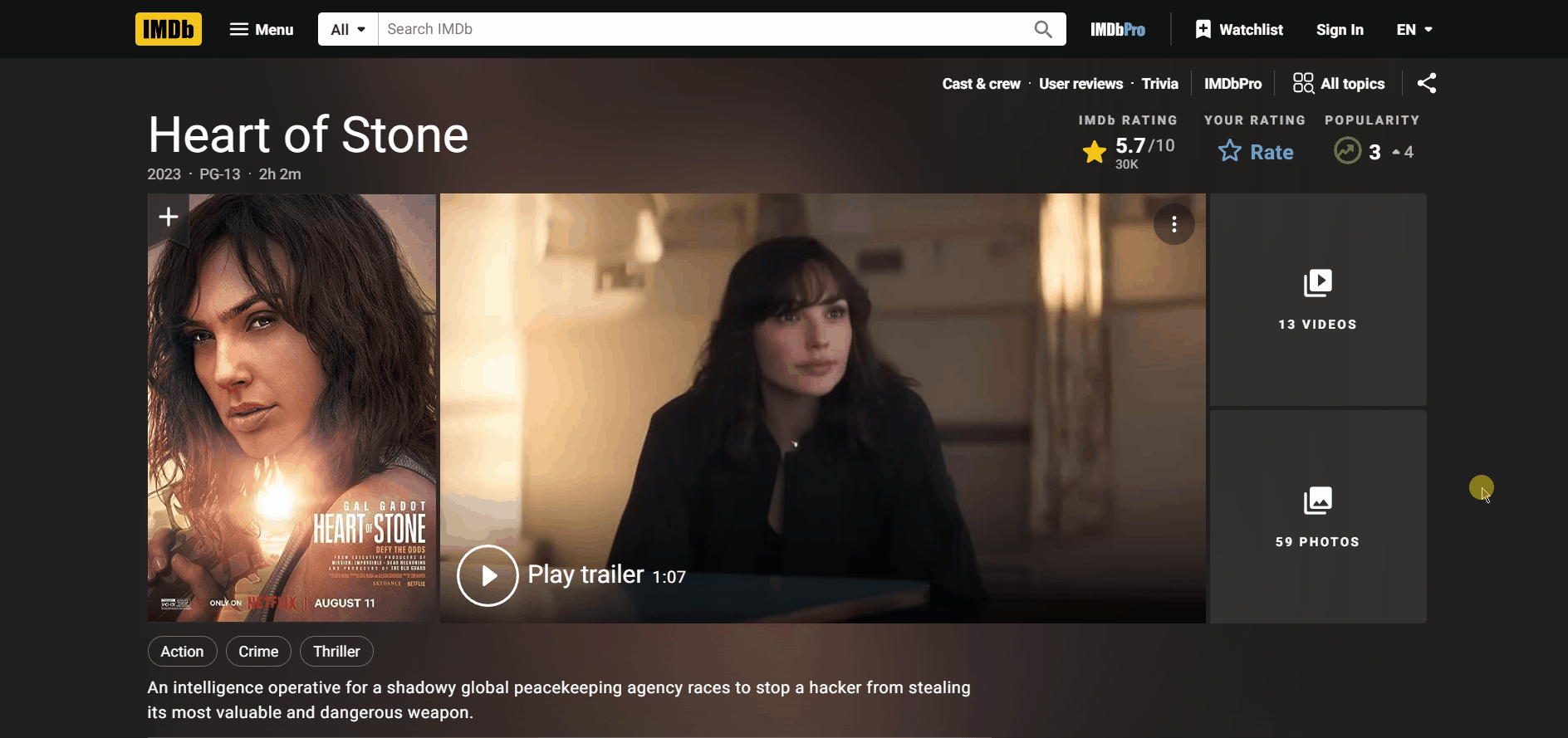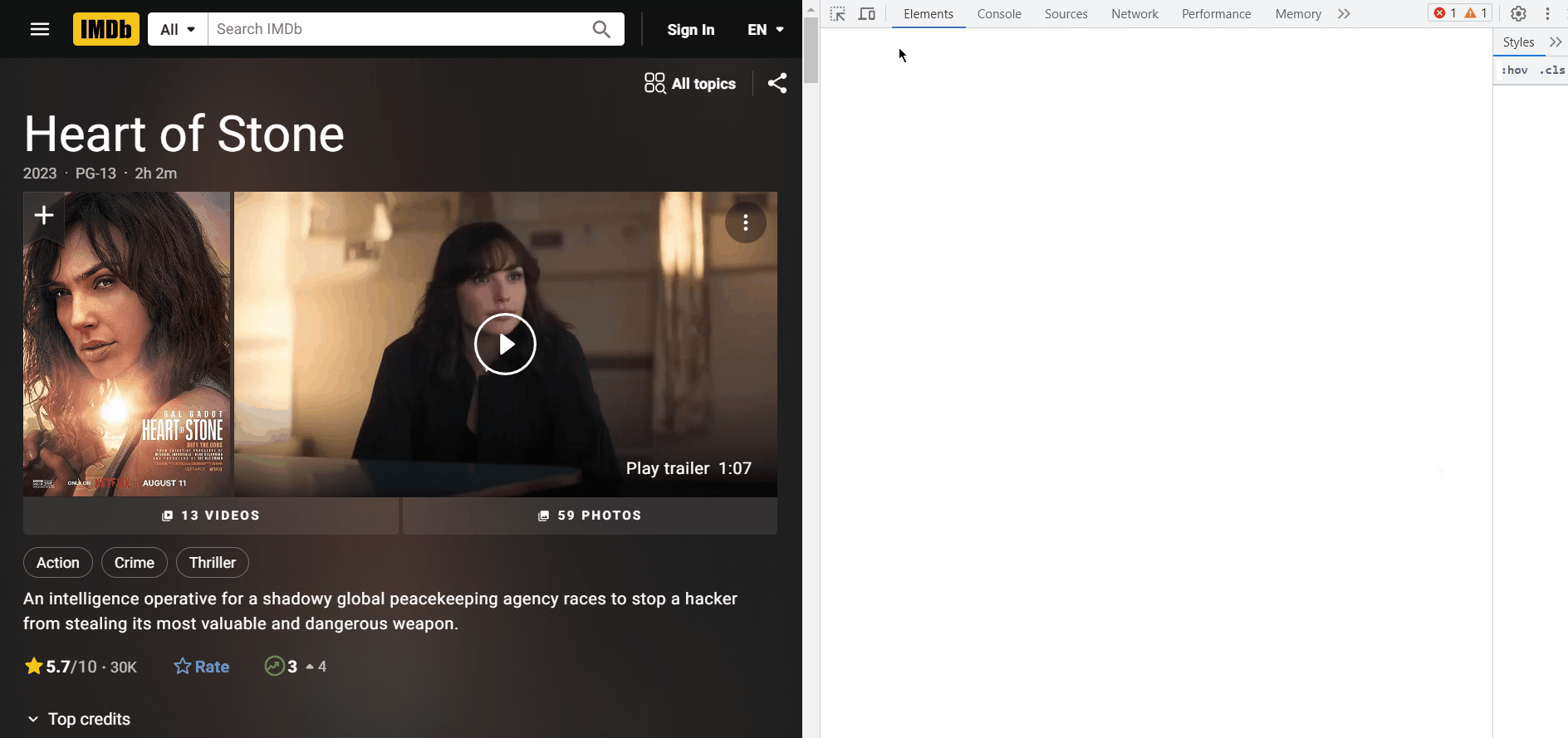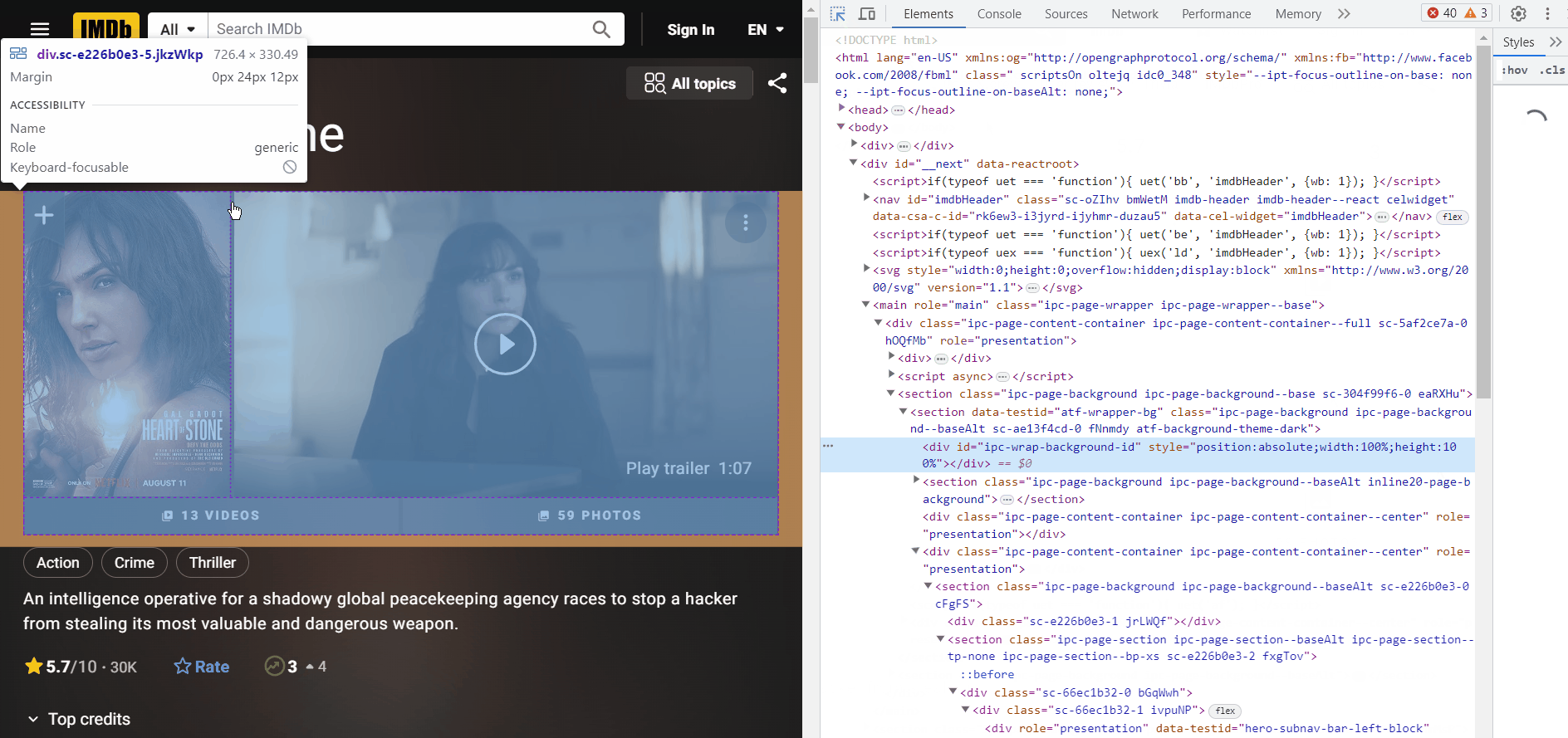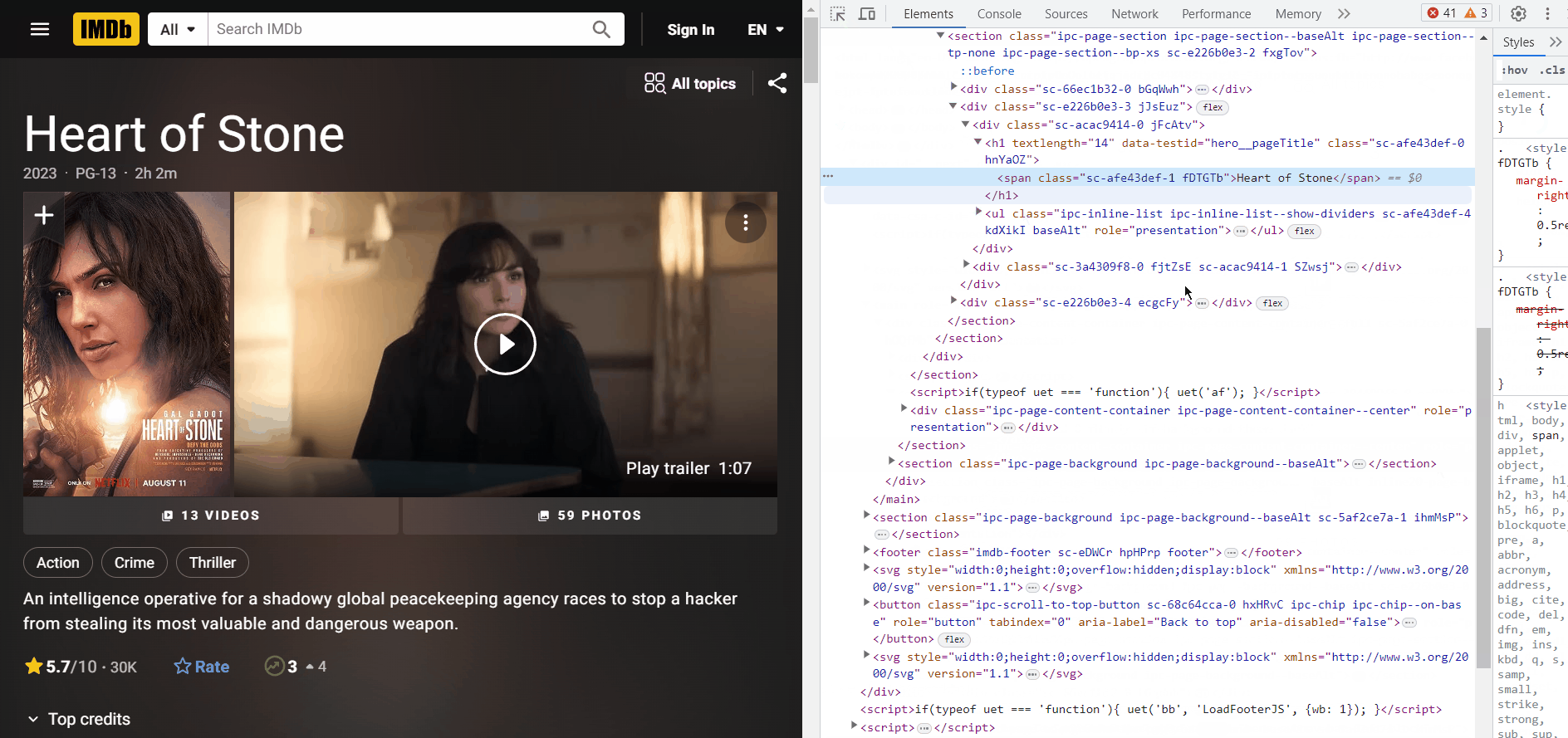
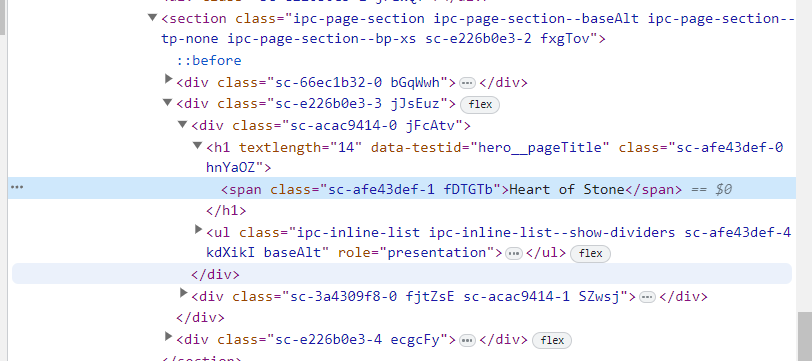
Inspect the title and you will find that title is inside a span tag which is inside a h1 tag with data-testid attribute “hero__pageTitle”.
Note: we didn’t use class name of span because the class name is dynamic (changes). We need consistent information so that we can apply it to all the movies. In this case ‘hero__pageTitle’ seems to be consistent for all the detail page.
Now that we analyzed how the title is placed in the html. Lets grab it. Add the following to your code.
title = response.xpath('//h1[@data-testid = "hero__pageTitle"]/span/text()').get()You got your title text. Similarly, Now lets get the ratings and other details.
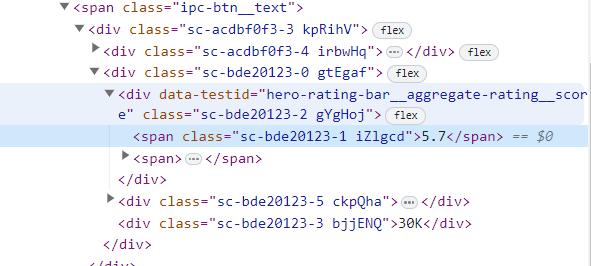
rating_score = response.xpath('//div[@data-testid= "hero-rating-bar__aggregate-rating__score"]/span/text()').get()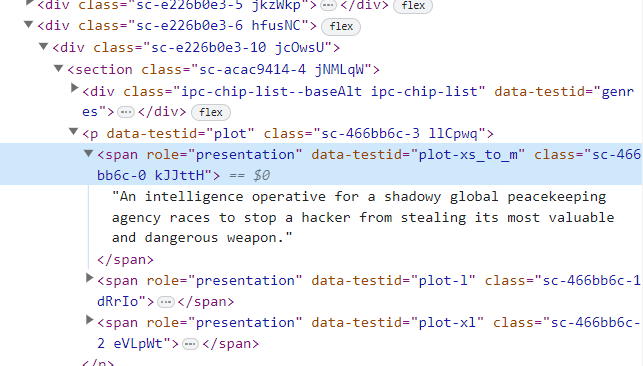
summary = response.xpath('//span[@data-testid="plot-xl"]/text()').get()Everything should be smooth at this point. Now lets see how we can grab casts. There is no specific class name for directors and other casts. so we will be trying to get the names using texts. For that lets select a element that has all the casts.
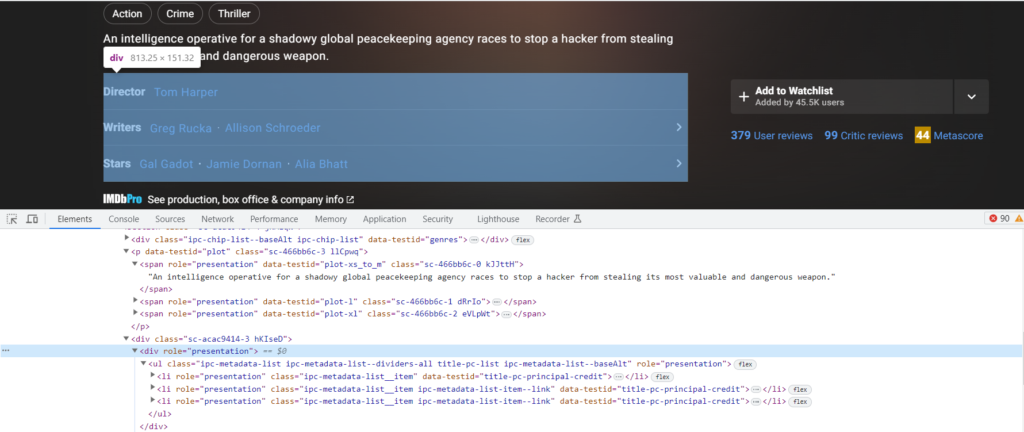
cast_details = response.xpath('//div[@role = "presentation"]')Now lets see How can you grab the required data.

You can see that Director name ‘Tom Harper’ is inside a ‘a’ tag which is inside a ‘li’ tag which is also inside a ‘ul’ tag inside a ‘div’ tag.
The ‘div’ tag is sibling of ‘span’ tag containing text as ‘Director’. You can better understand it by code.
director = cast_details.xpath('//li[@role="presentation"]*/[text() ="Director"]/following-sibling::div//li[@role= "presentation"]/a/text()').get()
writers = cast_details.xpath('//li[@role="presentation"]*/[text() ="Writer"]/following-sibling::div//li[@role=
"presentation"]/a/text()').getall()
stars = cast_details.xpath('//li[@role="presentation"]*/[text() ="Stars"]/following-sibling::div//li[@role= "presentation"]/a/text()').getall()Writers and Stars can be extracted by the same way.
In the list, both ‘writers’ and ‘stars’ are repeated frequently. To obtain only the unique items, add the following code.
writer_newlist = []
for i in writers:
if i not in writer_newlist:
writer_newlist.append(i)
stars_newlist = []
for i in stars:
if i not in stars_newlist:
stars_newlist.append(i) Now that we have all the required information in variables. Lets yield it. If you want other data, you can similarly code it.
yield {
'Url' : response.url,
'Title' : title,
'Rating' : rating_score ,
'summary' : summary ,
'Director' : director,
'Writer' : writer_newlist ,
'Stars' : stars_newlist
}Now, We have finished the coding part.
7. Running Scrapy Code.
scrapy crawl moviescraper -O data.csvNow to run the code. Start your terminal in the current folder and hit the above command.
Your script is now running and as you can see its getting all the information. Also, check your file to confirm its extracting the right information.
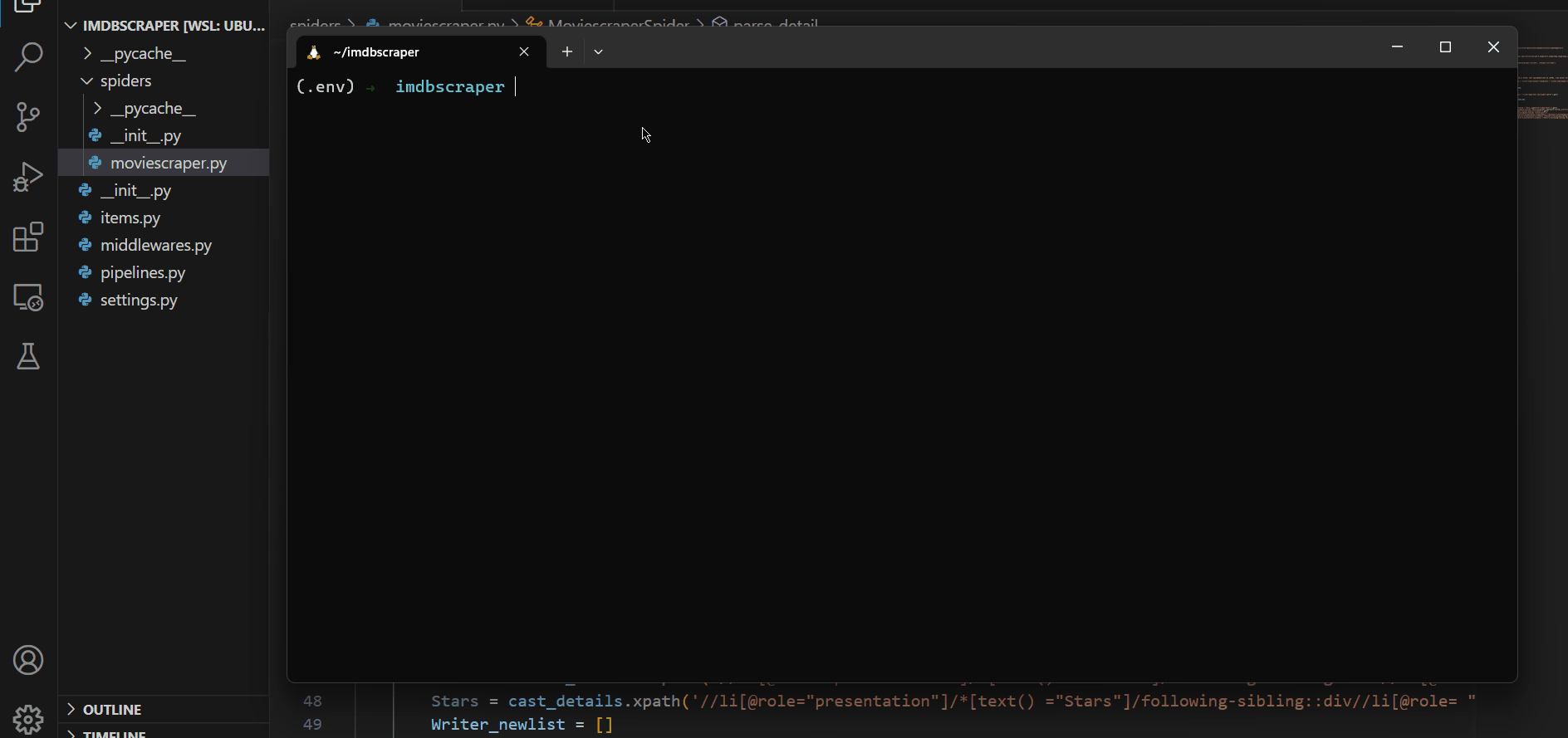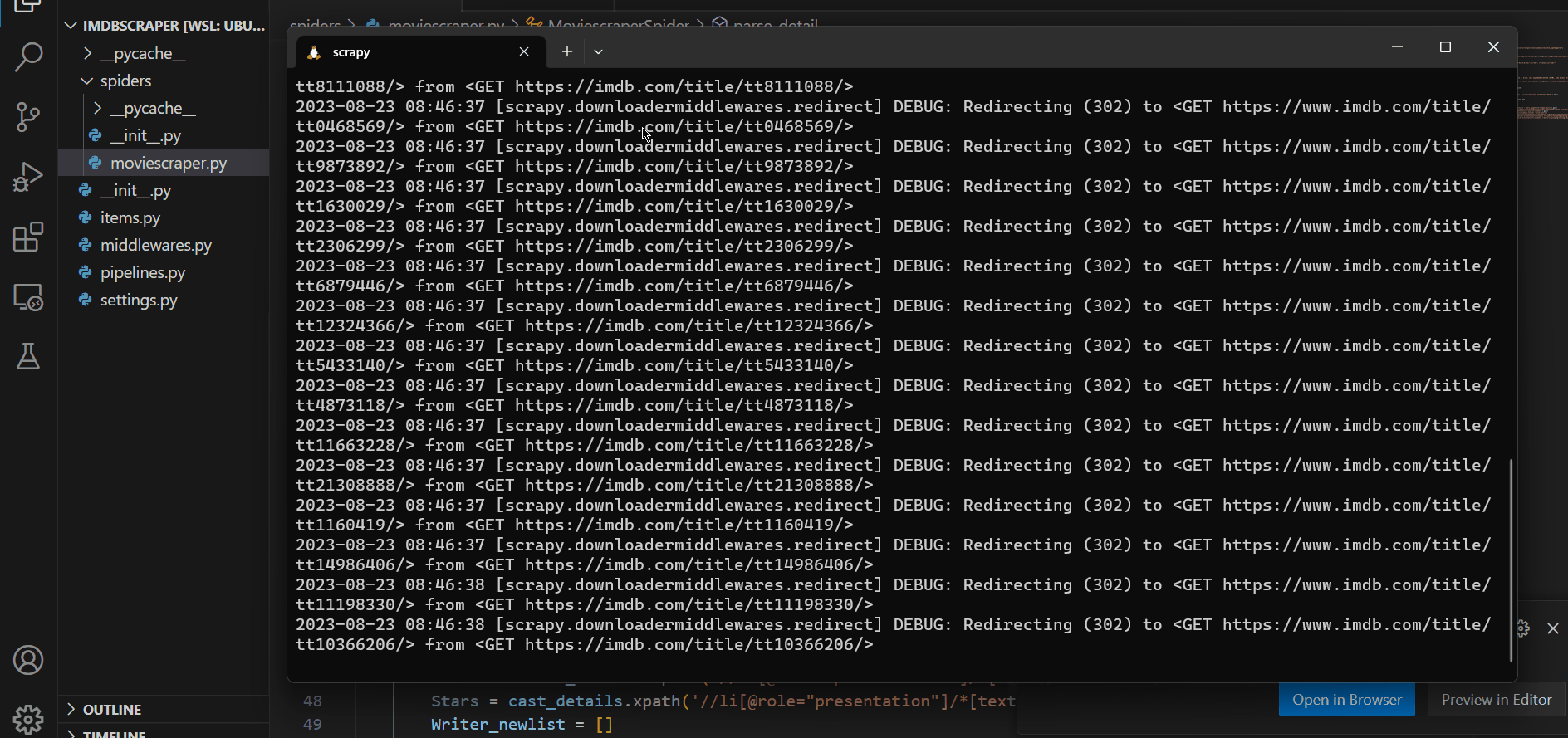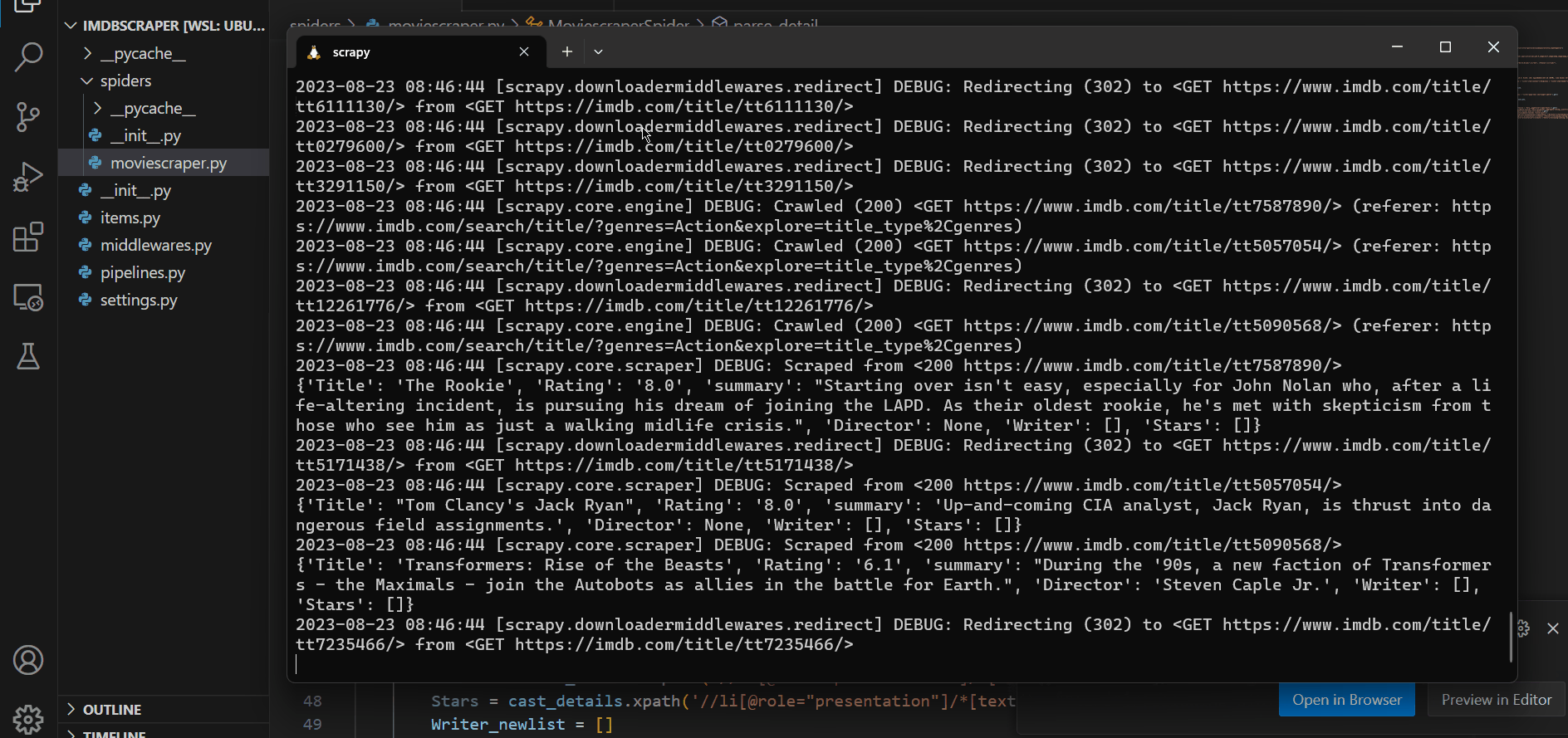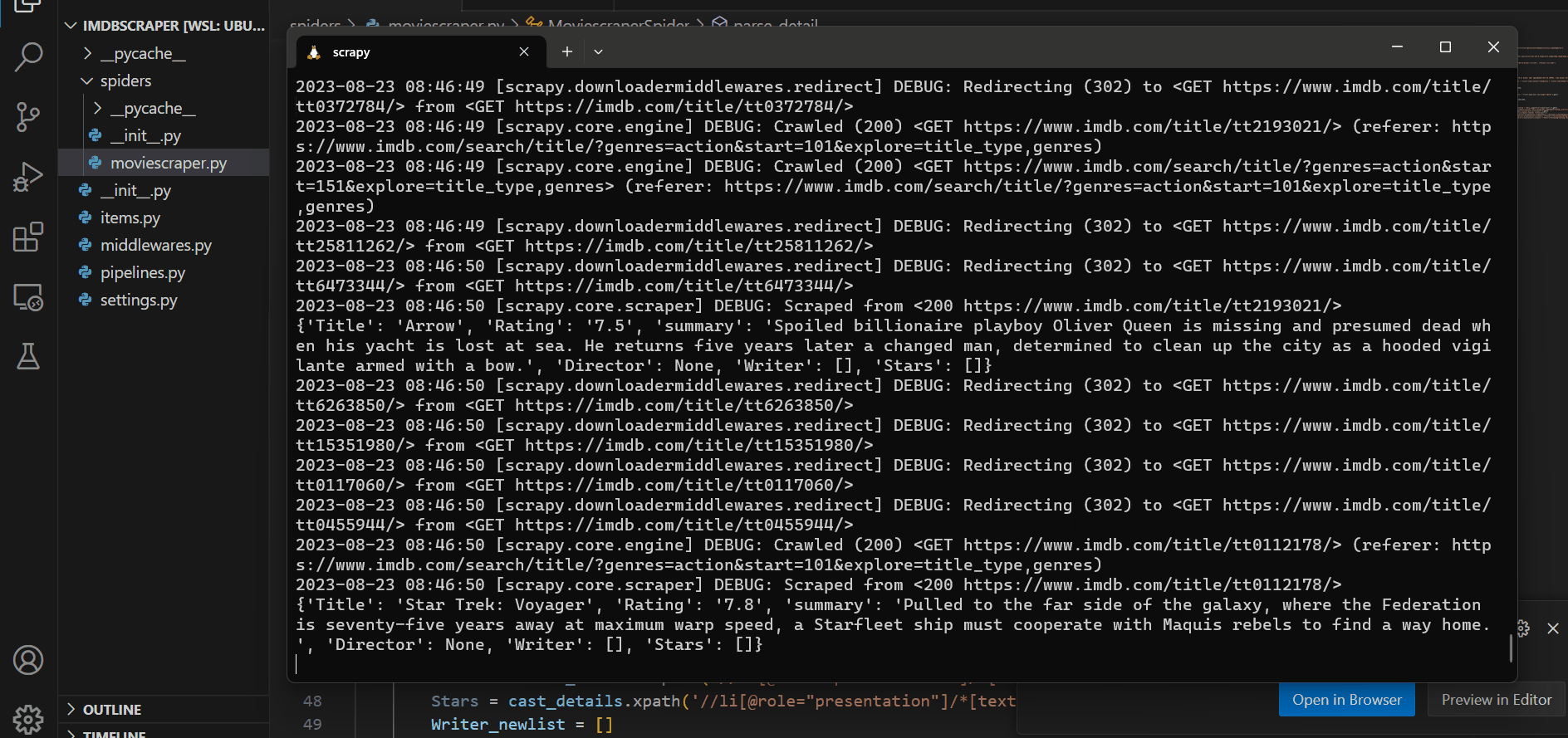
Note: Just Hit ctrl + c if you want to finish scraping.
Here is the extracted data.

8. Conclusion.
You have successfully scraped data from IMDB. Congratulations, Mission Accomplished ! If you have any doubts or problems, feel free to comment down. We will surely reply your queries.
P.S : We are a data scraping/mining company. If you want to contact us for any scraping work then feel free to do so. Cheers!
Common Errors:
- Sometimes some scraper has to follow ‘robots.txt’ which is a guideline for crawlers. You can set it to ‘False’ by going into the settings if you encounter any issues. Also, its important to mention that while its legal not follow guidelines by the website but its usually seen unethical to do so.
- 403/302 status code error is usually seen because of missing headers, body or cookies. So you can add them while requesting for the response.
- It should be mentioned that, If the html structure of any page changes , the scraper may face some difficulty while scraping. So you may need to write updated code in that situation.







